Image via Unknown
Thursday, October 30, 2025
OpenAI's Open Safety Models Are Here
We're watching a fascinating shift in how AI safety and design actually work: OpenAI dropped gpt-oss-safeguard for customizable safety classification, while Adobe just obliterated the line between prompts and design tools (yikes, goodbye traditional interfaces). Meanwhile, the infrastructure race is heating up with AWS launching Project Rainier to power Anthropic's Claude, but here's the wild part: AI labs are apparently using Mercor to grab training data companies won't voluntarily share, and Anthropic just discovered their models might actually be introspecting on themselves. So if your AI can think about its own thinking, and companies are getting data through marketplaces instead of partnerships, what happens to trust in this whole ecosystem?
Image via Unknown
Top Stories
TLDR Newsletter
OpenAI open-sourced gpt-oss-safeguard, reasoning-based safety models that apply custom policies at inference time rather than requiring retraining, offering developers flexible and explainable content moderation tailored to their specific use cases.
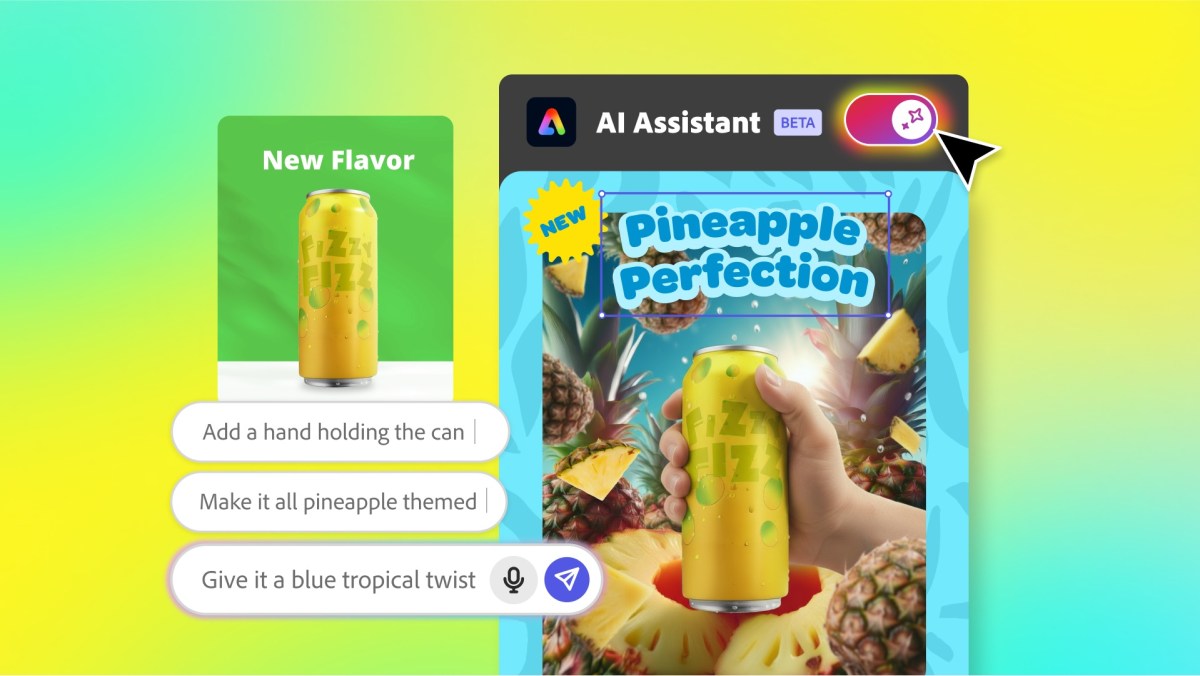
Adobe is redesigning how users interact with AI in creative tools by seamlessly blending prompt-based generation with traditional editing, targeting both accessibility for students and control for professionals.
TechCrunch
Mercor bypasses corporate data gatekeeping by paying industry experts to share their knowledge with AI labs, creating a $10 billion marketplace that threatens established firms' competitive advantages while walking a legal and ethical tightrope around corporate espionage.
Anthropic
Anthropic's research provides direct evidence that advanced Claude models can introspect on their own internal states with limited reliability, detected through concept injection experiments showing models recognize injected thoughts before mentioning them. This capability could improve AI transparency and debugging, though the mechanism remains mysterious and validation methods need development.
About Amazon
AWS's Project Rainier, a massive AI compute cluster of 500,000+ Trainium2 chips, is now powering Anthropic's Claude development and represents a watershed moment in AI infrastructure deployment, enabled by AWS's end-to-end control of hardware and software systems.
Keep Reading
Enjoyed this issue?
Get daily AI intel delivered to your inbox. No fluff, just the stories that matter.